Machine Learning - KNN
K-Nearest Neighbor Classifier (KNN)¶
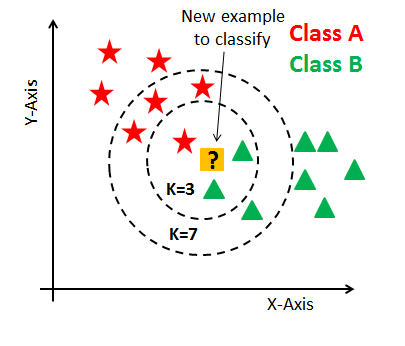
1-1. 데이터 포인트 간의 거리 - 2D¶
KNN 모델로 영화 평가 분류기를 구현합니다.
두 점이 서로 가깝거나 멀리 떨어져 있는 정도를 측정하기 위해 거리 공식을 사용할 것입니다.
이 예제의 경우 데이터의 차원은 다음과 같습니다.
- 영화의 러닝타임
- 영화 개봉 연도
스타워즈와 인디아나 존스를 예로 들겠습니다. 스타워즈는 125분이며 1977년에 개봉했습니다. 인디아나 존스는 115분이며 1981년에 개봉했습니다.
이 두 영화를 의미하는 두 데이터 포인트들의 거리는 아래와 같이 계산됩니다. $$\sqrt{(125 - 115)^2 + (1977-9181)^2} = 10.77$$
Practice 1¶
movie1과movie2라는 두 리스트을 매개 변수로 사용하는distance라는 함수를 선언합니다.각 리스트의 첫 번째 인덱스는 영화의 러닝타임이고 두 번째 인덱스는 영화의 개봉 연도입니다.
distance함수는 두 리스트 사이의 거리를 반환해야 합니다.
# distance 함수 구현하기
def distance(movie1, movie2):
length_difference = (movie1[0] - movie2[0]) ** 2
year_difference = (movie1[1] - movie2[1]) ** 2
distance = (length_difference + year_difference) ** 0.5
return distance
- 아래 영화에 대해
distance함수를 호출하여 거리를 비교해봅니다.
star_wars = [125, 1977]
raiders = [115, 1981]
mean_girls = [97, 2004]
# star_wars와 raiders의 거리
print(distance(star_wars, raiders))
# star_wars와 mean_girls의 거리
print(distance(star_wars, mean_girls))
# 스타워즈는 어느 영화와 더 비슷합니까?
# 정답:
10.770329614269007 38.897300677553446
1-2. 데이터 포인트 간의 거리 - 3D¶
영화의 길이와 개봉일만을 기준으로 영화 평가 분류기를 만드는 것은 상당히 제한적입니다. 영화의 다른 속성을 데이터에 포함하여 세번째 차원을 추가해 보겠습니다.
추가된 세 번째 차원은 영화 예산입니다. 이제 영화를 나타내는 두 데이터 포인트들의 거리를 3차원으로 찾아야 합니다.

데이터의 차원이 삼차원보다 많아지면 시각화 하는 것은 어렵지만 그래도 거리를 구할 수 있습니다.
N차원의 데이터 포인트 A와 B 사이의 거리 공식은 다음과 같습니다.
$$\sqrt{(A_1 - B_1)^2 + (A_2 - B_2)^2 + ... + (A_n - B_n)^2}$$여기서 $A_1 - B_1$은 각 데이터 포인트의 첫 번째 feature 간의 차입니다. $A_n - B_n$은(는) 각 점의 마지막 feature 간의 차입니다.
이 공식을 이용하면 N차원 공간에서 한 데이터 포인트의 K-Nearest Neighbors를 찾을 수 있습니다.
이 거리를 사용하여 label되지 않은 데이터 포인트의 가장 가까운 이웃을 찾아 결과적으로 분류를 하게 됩니다.
Practice 2¶
distance함수를 N개의 차원의 데이터의 거리를 반환하는 함수로 수정합니다.
# distance 함수 수정
def distance(movie1, movie2):
squared_difference = 0
for i in range(len(movie1)):
squared_difference += (movie1[i] - movie2[i]) ** 2
final_distance = squared_difference ** 0.5
return final_distance
- 위 활동에서 주어진 영화들에 영화 예산 속성이 추가되었습니다. 아래 영화에 대해
distance함수를 호출하여 거리를 비교해봅니다.
star_wars = [125, 1977, 11000000]
raiders = [115, 1981, 18000000]
mean_girls = [97, 2004, 17000000]
# star_wars와 raiders의 거리
print(distance(star_wars, raiders))
# star_wars와 mean_girls의 거리
print(distance(star_wars, mean_girls))
# 스타워즈는 어느 영화와 더 비슷합니까?
# 정답: mean girls
7000000.000008286 6000000.000126083
1-3. 척도가 다른 데이터: 정규화¶
이 활동에서는 K-Nearest Neighborhood 알고리즘의 첫 번째 단계를 구현합니다.
- 데이터를 정규화합니다.
- 가장 가까운 이웃인
k를 찾습니다. - 이러한 이웃을 기준으로 새로운 포인트를 분류합니다.
우리가 영화 예산 속성을 추가하면 데이터의 범위가 변화한것을 확인할 수 있습니다.
영화 개봉 연도와 영화 예산을 살펴보겠습니다. 어떠한 두 영화의 개봉 날짜의 최대 차이는 약 125년입니다((루미에르 브라더스는 1890년대에 영화를 만들고 있었습니다). 하지만, 어떠한 두 영화의 예산 차이는 수백만 달러가 될 수 있습니다.
거리 공식의 문제는 규모에 상관없이 모든 차원을 동등하게 취급한다는 것입니다. 이는 1년 차이가 나는 영화 개봉 년도를 1달러의 차이의 영화 예산과 같은 정도로 취급한다는 뜻입니다.
이 문제에 대한 해결책은 정규화입니다. 이는 모든 값은 0과 1 사이로 변환합니다.

이번 실습은 최소-최대 정규화(Min-Max Normalization)를 사용할 것입니다.
$$x_{norm} = \frac{x-min(x)}{max(x)-min(x)}$$참고: scikit-learn MinMaxScaler
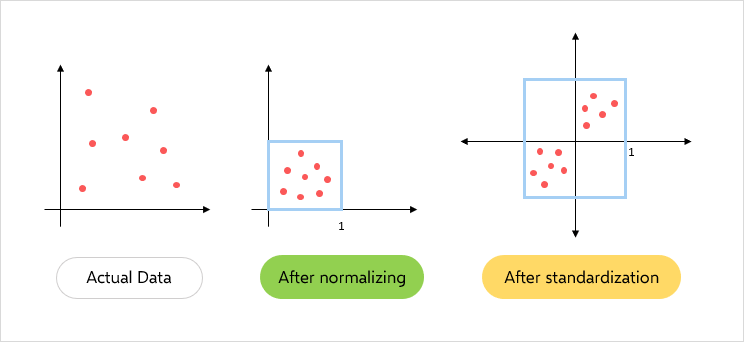
Practice 3¶
# min_max_normalize 함수 구현
def min_max_normalize(lst):
# 1.
minimum = min(lst)
maximum = max(lst)
# 2.
normalized = []
for value in lst:
normalized_num = (value - minimum) / (maximum - minimum)
normalized.append(normalized_num)
return normalized
release_dates = [1897, 1998, 2000, 1948, 1962, 1950, 1975, 1960,
2017, 1937, 1968, 1996, 1944, 1891, 1995, 1948,
2011, 1965, 1891, 1978]
from pprint import pprint
# 결과값 출력하기
pprint(min_max_normalize(release_dates))
[0.047619047619047616, 0.8492063492063492, 0.8650793650793651, 0.4523809523809524, 0.5634920634920635, 0.46825396825396826, 0.6666666666666666, 0.5476190476190477, 1.0, 0.36507936507936506, 0.6111111111111112, 0.8333333333333334, 0.42063492063492064, 0.0, 0.8253968253968254, 0.4523809523809524, 0.9523809523809523, 0.5873015873015873, 0.0, 0.6904761904761905]
1-4. Nearest Neighbors 찾기¶
K-Nearest Neighbors 알고리즘의 두번째 단계를 구현해보겠습니다.
- 데이터를 정규화합니다.
- 가장 가까운 이웃
k를 찾습니다. - 이러한 이웃을 기준으로 새로운 포인트를 분류합니다.
Label되지 않은 데이터 포인터를 분류하기 위해서는 이 데이터 포인트와 가장 가까운 k개의 이웃을 찾아야 합니다. 가장 적합한 k를 찾는 방법도 있지만, 일단은 k=5로 정하도록 하겠습니다.
가장 가까운 5개의 이웃을 찾기 위해서는 label되지 않은 데이터 포인트를 데이터의 다른 모든 데이터 포인트와의 거리를 계산하여 비교합니다. 이번 실습에서 구현할 함수의 반환값은 label되지 않은 한 영화에 대해 데이터의 모든 영화와의 거리가 정렬된 리스트입니다.
반환값의 예시는 다음과 같습니다.
[
[0.30, 'Superman II'],
[0.31, 'Finding Nemo'],
...
...
[0.38, 'Blazing Saddles']
]
이 예에서 label되지 않은 영화와 슈퍼맨2 영화와의 거리는 0.30입니다.
# 영화 데이터 받아오기
import urllib.request
import ast
movie_dataset_url = "https://raw.githubusercontent.com/inikoreaackr/ml_datasets/main/movie_dataset.txt"
movie_datasets = []
for line in urllib.request.urlopen(movie_dataset_url):
movie_datasets.append(line.decode('utf-8'))
movie_dataset = ast.literal_eval(movie_datasets[0][16:])
movie_labels = ast.literal_eval(movie_datasets[1][15:])
Practice 4¶
위에 주어진 영화 데이터 중
The Avengers영화를 출력해봅니다. 각 영화의 세 가지 feature은 다음과 같습니다.- 정규화된 영화 예산(달러)
- 정규화된 러닝타임(분)
- 정규화된 개봉 연도
위 데이터의 label은 좋은 영화와 나쁜 영화를 나타냅니다.
The Avengers영화의 label은 1로, 좋은 영화입니다. 분류 기준은 IMDb에서 7.0 이상의 평가를 받으면 좋은 영화로 분류됩니다.
print(movie_dataset['The Avengers'])
print(movie_labels['The Avengers'])
[0.018009887923225047, 0.4641638225255973, 0.9550561797752809] 1
- classify 함수를 선언하고 구현해봅니다.
# classify 함수를 구현
def classify(unknown, dataset, k):
distances = []
#Looping through all points in the dataset
for title in dataset:
movie = dataset[title]
distance_to_point = distance(movie, unknown)
#Adding the distance and point associated with that distance
distances.append([distance_to_point, title])
distances.sort()
#Taking only the k closest points
neighbors = distances[0:k]
return neighbors
아래 주어진 매개변수로
classify함수를 테스트하고 결과를 출력합니다.[.4, .2, .9]movie_dataset5
# `classify` 함수를 테스트하고 결과를 출력합니다.
print(classify([.4, .2, .9], movie_dataset, 5))
[[0.08273614694606074, 'Lady Vengeance'], [0.22989623153818367, 'Steamboy'], [0.23641372358159884, 'Fateless'], [0.26735445689589943, 'Princess Mononoke'], [0.3311022951533416, 'Godzilla 2000']]
1-5. Neighbors 세기¶
이 활동에서는 K-Nearest Neighbor 알고리즘 중 마지막 단계를 구현합니다.
- 데이터를 정규화합니다.
- 가장 가까운 이웃인
k를 찾습니다. - 이웃을 기준으로 새로운 포인트를 분류합니다
이전 활동에서 어떠한 label되지 않은 데이터 포인트에 대해 가장 가까운 이웃 k개를 찾아 다음과 같은 형태로 리스트에 저장했습니다.
[
[0.083, 'Lady Vengeance'],
[0.236, 'Steamboy'],
...
...
[0.331, 'Godzilla 2000']
]
이 리스트의 좋고 나쁜 영화의 갯수를 셈으로써 분류를 할 수 있습니다. 만약 좋은 영화로 분류된 이웃들의 갯수가 더 많아면, label되지 않은 영화는 좋은 영화로 분류됩니다. 반대의 경우에는 나쁜 영화로 분류됩니다.
만약 좋은 영화로 분류된 이웃들의 갯수와 나쁜 영화로 분류된 이웃들의 갯수가 같다면 가장 거리가 가까운 영화의 label을 선택하게 됩니다.
Practice 5¶
- 이 활동에서는 위의
classify함수를 수정하여unknown데이터 포인트에 대한 분류값을 반환하겠습니다.labels매개 변수를classify함수에 추가합니다.
num_good와num_bad라는 두 변수를 만들고 각각0으로 초기화합니다.
labels과title을 사용하여 각 영화의 label을 받아옵니다.- 해당 라벨이
0이면num_bad에1을 증가시킵니다. - 해당 라벨이
1이면num_good에1을 증가시킵니다.
- 해당 라벨이
이제 label되지 않은 영화를 분류할 수 있습니다.
num_good가num_bad보다 크면1을 반환합니다.- 그렇지 않으면
0을 반환합니다.
# classify 함수 수정하기
# 1.
def classify(unknown, dataset, labels, k):
distances = []
for title in dataset:
movie = dataset[title]
distance_to_point = distance(movie, unknown)
#Adding the distance and point associated with that distance
distances.append([distance_to_point, title])
distances.sort()
#Taking only the k closest points
neighbors = distances[0:k]
# 2.
num_good = 0
num_bad = 0
# 3.
for neighbor in neighbors:
title = neighbor[1]
if labels[title] == 0:
num_bad += 1
elif labels[title] == 1:
num_good += 1
# 4.
if num_good > num_bad:
return 1
else:
return 0
다음 파라미터를 사용하여
classify함수를 호출하여 결과를 출력해봅니다.- 분류하려는 영화는
[.4, .2, .9]입니다. - 훈련 데이터는
movie_dataset입니다. - 훈련 데이터의 label은
movie_labels입니다. k는 5로 지정합니다.
- 분류하려는 영화는
# `classify` 함수를 테스트하고 결과를 출력합니다.
print(classify([.4, .2, .9], movie_dataset, movie_labels, 5))
1
1-6. 하나의 데이터 포인트 분류하기¶
위의 활동까지는 임의의 데이터인 [.4, .2, .9]에만 테스트 해보았습니다. 이번 활동에서는 실제 영화 Call Me By Your Name 데이터를 정규화하고 예측해 볼 것입니다.
- 먼저 분류하고자 하는 영화가 훈련 데이터에 있지는 않은지 확인해야 합니다.
# "Call Me By Your Name"이 훈련 데이터에 있는지 확인하기
print("Call Me By Your Name" in movie_dataset)
False
분류하고자 하는 영화가 훈련 데이터에 없는 것으로 확인 되면
my_movie변수를 생성하고 영화 예산, 러닝타임, 개봉 연도의 순으로 데이터를 구성합니다.Call Me By Your Name의 예산은 35만 달러, 런타임은 132분, 개봉 연도는 2017년입니다.
# my_movie 변수 생성하기
my_movie = [3500000, 132, 2017]
- 주어진
normalize_dimension함수를 사용하여my_movie를 정규화합니다.normalized_my_movie라는 변수를 만들고 my_movie의 정규화된 값을 저장합니다. 결과를 출력해봅니다.
# x, y, z points array 받아오기
import urllib.request
import ast
import numpy as np
points_url = "https://raw.githubusercontent.com/inikoreaackr/ml_datasets/main/points_xyz.txt"
points = []
for line in urllib.request.urlopen(points_url):
points.append(line.decode('utf-8'))
training_x = np.array(ast.literal_eval(points[0]))
training_y = np.array(ast.literal_eval(points[1]))
training_z = np.array(ast.literal_eval(points[2]))
def normalize_dimension(value, lst):
minimum = min(lst)
maximum = max(lst)
return (value - minimum) / (maximum - minimum)
def normalize_point(pt):
global training_x
global training_y
global training_z
newx = normalize_dimension(pt[0], training_x)
newy = normalize_dimension(pt[1], training_y)
newz = normalize_dimension(pt[2], training_z)
return [newx, newy, newz]
# my_movie 변수를 정규화합니다.
normalized_my_movie = normalize_point(my_movie)
print(normalized_my_movie)
[0.00028650338197026213, 0.3242320819112628, 1.0112359550561798]
normalized_my_movie,movie_dataset,movie_labels,k=5매개 변수를 사용하여 "classify"를 호출하고 결과를 출력합니다.
# classify 함수를 호출합니다.
classify(normalized_my_movie, movie_dataset, movie_labels, 5)
# TODO: Call Me By Your Name 영화의 분류된 lable은 무엇인가요?
# 정답:
1
1-7. scikit-learn으로 KNN 구현하기¶
import pandas as pd
data_url = 'https://raw.githubusercontent.com/inikoreaackr/ml_datasets/master/breastcancer.csv'
df = pd.read_csv(data_url)
df.head()
| id | diagnosis | radius_mean | texture_mean | perimeter_mean | area_mean | smoothness_mean | compactness_mean | concavity_mean | concave points_mean | ... | texture_worst | perimeter_worst | area_worst | smoothness_worst | compactness_worst | concavity_worst | concave points_worst | symmetry_worst | fractal_dimension_worst | Unnamed: 32 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 842302 | M | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | NaN |
| 1 | 842517 | M | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | NaN |
| 2 | 84300903 | M | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | NaN |
| 3 | 84348301 | M | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | NaN |
| 4 | 84358402 | M | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | NaN |
5 rows × 33 columns
# id 와 Unnamed: 32 column을 삭제한 후 column들의 리스트를 출력합니다.
df.drop(columns=['id', 'Unnamed: 32'], inplace=True)
df.columns
Index(['diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se', 'texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst',
'perimeter_worst', 'area_worst', 'smoothness_worst',
'compactness_worst', 'concavity_worst', 'concave points_worst',
'symmetry_worst', 'fractal_dimension_worst'],
dtype='object')
# 각 column에 na 값이 있지는 않은지 확인합니다.
df.isna().any()
diagnosis False radius_mean False texture_mean False perimeter_mean False area_mean False smoothness_mean False compactness_mean False concavity_mean False concave points_mean False symmetry_mean False fractal_dimension_mean False radius_se False texture_se False perimeter_se False area_se False smoothness_se False compactness_se False concavity_se False concave points_se False symmetry_se False fractal_dimension_se False radius_worst False texture_worst False perimeter_worst False area_worst False smoothness_worst False compactness_worst False concavity_worst False concave points_worst False symmetry_worst False fractal_dimension_worst False dtype: bool
# label이 어떻게 구성되어있나 봅니다.
df['diagnosis'].value_counts()
B 357 M 212 Name: diagnosis, dtype: int64
# 데이터를 X와 y로 나누고 train, test 셋으로 나눕니다.
from sklearn.model_selection import train_test_split
y = df['diagnosis']
X = df.drop(columns=['diagnosis'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=True)
# scikit-learn의 KNN classifier을 생성하고 훈련시킵니다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
KNeighborsClassifier()
# test 셋에 대하여 정확도를 출력해봅니다.
knn.score(X_test, y_test)
0.9590643274853801
1-8. 가장 적합한 k 찾기¶
n_neighbors_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
score = []
# 가장 적합한 k를 찾아봅니다.
for k in n_neighbors_list:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
score.append(knn.score(X_test, y_test))
n_neighbors_list[np.argmax(score)]
9
import matplotlib.pyplot as plt
plt.plot(n_neighbors_list, score)
[<matplotlib.lines.Line2D at 0x7f0adc331190>]


Comments